
Datenintegrität & KI: Alte Erkenntnisse, neue Anwendung
Essenz
Die Herausforderungen der KI-Datennutzung sind nicht neu – bewährte Best Practices aus drei Jahrzehnten Datenmanagement, besonders in den Bereichen Datenqualität und Governance, sind der Schlüssel für erfolgreiche KI-Implementierungen.
Künstliche Intelligenz ist in aller Munde – und das zu Recht. Die meisten von uns haben bereits erlebt, wie Generative AI und die zugrundeliegenden Large Language Models (LLMs) unsere Art zu arbeiten revolutionieren.
Doch mit dem KI-Hype kommen auch berechtigte Fragen auf: Ist KI wirklich produktionsreif? Sind die Antworten vertrauenswürdig? Nutzen die Modelle alle relevanten Daten und Kontexte? Können sie unvoreingenommen arbeiten? (Von den bizarren Geschichten über KI-Halluzinationen ganz zu schweigen!) Und nicht zuletzt: Dürfen wir alle diese Daten überhaupt nutzen, oder gibt es urheberrechtliche und datenschutzrechtliche Bedenken?
Diese Fragen drehen sich um Zugänglichkeit, Qualität und Governance von KI-Daten. Neu sind diese Herausforderungen jedoch nicht. Die Geschichte wiederholt sich – und bewährte Best Practices aus drei Jahrzehnten lassen sich auch auf die KI-Herausforderungen von heute anwenden.
Hinweis: Dieser Artikel behandelt komplexe Technologien stark vereinfacht. Ziel ist es zu zeigen, wie Best-Practices zur Datenintegrität sich immer wieder bewährt haben – unabhängig von der jeweiligen Technologie.

Am Anfang war das Data Warehouse
In den frühen 90ern revolutionierten Data Warehouses (DW) die Datenarchitektur. Die Idee war simpel: Wie können wir Transaktionsdaten aus Finanzen, Vertrieb, CRM und anderen isolierten Systemen besser nutzen? Eine konsolidierte Analyse war damals kaum möglich.
Die Magie des DW lag darin, Daten aus diesen Systemen zu extrahieren und analyseoptimiert neu zu strukturieren. Der ETL-Markt (Extract, Transform, Load) boomte, da er die nötigen Übersetzungen und Mappings bereitstellte.
Doch der reine Datentransfer reichte nicht. Jedes Quellsystem hatte eigene Regeln für Datenerfassung und -pflege. Bei der Zusammenführung ähnlicher Daten – etwa Kunden-, Adress- oder Produktdaten – gab es Konflikte.
Dies führte zur Einführung von Datenqualitäts-Software im DW-Umfeld. Ziel war es, durch Regeln die eingehenden Daten zu prüfen, zu bereinigen und zu standardisieren.
Mit wachsender Datenmenge entwickelten sich aus den Data Warehouses spezialisierte Data Marts für einzelne Geschäftsbereiche. Business Intelligence Tools ermöglichten die Datenanalyse für Endnutzer.
eBook
Verlässliche KI 101: Tipps, um Ihre Daten KI-fähig zu machen
Machen Sie Ihre KI mit Datenintegrität zukunftssicher. Es ist an der Zeit, das Potenzial Ihrer KI-Initiativen voll auszuschöpfen. Lassen Sie sich von wertvollen KI-Anwendungsfällen inspirieren und erfahren Sie, wie Sie ungenaue Ergebnisse und andere große Herausforderungen überwinden.
Dann kamen Big Data & Hadoop
Die Internet-Ära brachte neue Herausforderungen durch unstrukturierte Daten. Als die Datenmengen explodierten, führte dies zur Big-Data-Revolution mit Hadoop. Doch mangelnde Datenqualität verwandelte viele Hadoop-Systeme in “Datensümpfe”.
Als Lösung entstanden Data Lakes für Rohdaten aller Art und Data Lakehouses für strukturierte Geschäftsberichte. Die zentrale Erkenntnis blieb: Ohne saubere Daten und klare Governance funktioniert kein System – egal welche Technologie.
Diese Entwicklung setzt sich heute mit KI fort: LLMs als zentrale Wissensspeicher, SLMs als spezialisierte Modelle für konkrete Geschäftszwecke und GenAI als neue Form der Datenabfrage.
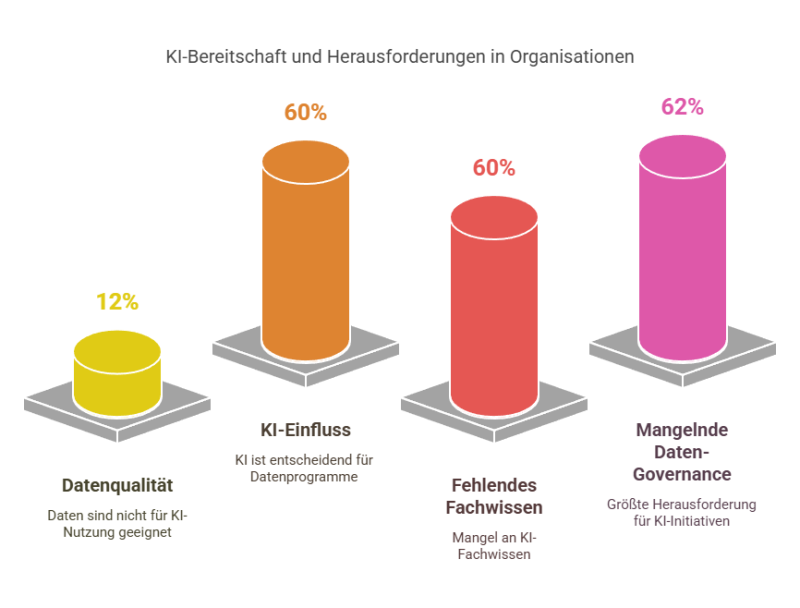
Und jetzt: KI und Large Language Models
KI wird unsere Arbeit weiter transformieren. Organisationen entwickeln gerade Richtlinien für sichere und effektive KI-Nutzung. Auch staatliche Regulierungen werden folgen – besonders zu Urheberrecht und der Frage: Welche Daten sind öffentlich für KI-Training nutzbar, welche privat oder geschützt?
Die Geschichte wiederholt sich:
- LLMs sind die neuen Data Warehouses: Sie konsolidieren verschiedenste Daten in einem zentralen Wissens-Repository
- Small Language Models (SLMs) sind die neuen Data Marts: Fokussierte Modelle für spezifische Geschäftszwecke
- GenAI-Tools sind das neue BI und die neue Suche: Statt langer Ergebnislisten liefern sie direkte Antworten
- Datenmanagement-Best-Practices bleiben gleich: Datenintegration und -qualität sind weiterhin entscheidend
- Data Governance bleibt die wichtigste – und oftmals unreifste – Disziplin
KI wird den Bedarf an Data Governance nicht eliminieren – im Gegenteil. Wer heute in grundlegendes Datenmanagement investiert, wird morgen den größten Nutzen aus KI ziehen.
Mehr praktische Tipps finden Sie im E-Book: “Trusted AI 101: So machen Sie Ihre Daten KI-bereit“.

Experteneinschätzung für Ihre KI- und Datenanalyse-Initiativen 2025
Die wichtigsten Erkenntnisse: Datenintegrität ist für KI-Initiativen und bessere Entscheidungsfindung unerlässlich – aber das Vertrauen in Daten nimmt ab. Datenqualität und Data Governance sind...

Wie Sie Ihre KI-Projekte erfolgreich mit “sauberen” Daten vorantreiben
Kernpunkte: Vertrauenswürdige KI erfordert Datenintegrität. Um KI-fähige Daten zu erhalten, sollten Sie sich auf umfassende Datenintegration, Datenqualität und -verwaltung sowie Datenanreicherung...

Die richtige Datenintegrationslösung finden: Der Leitfaden
Die wichtigsten Erkenntnisse: Passen Sie sich schnell an Marktveränderungen an, indem Sie problemlos neue Datenquellen und -ziele hinzufügen und sicherstellen, dass sich Ihre IT-Landschaft mit dem...