
Talking about Large Language Models: A Summary of Considerations when Communicating
Artificial intelligence and machine learning have rapidly advanced in recent years, with large language models (LLMs) becoming increasingly prominent across various industries. However, with their growing presence comes the need for more in-depth discussion and understanding of their capabilities, limitations, and potential implications.
In the paper Talking About Large Language Models, Murray Shanahan from Imperial College London highlights the importance of caution when discussing LLMs and the potential dangers of anthropomorphizing them. Shanahan argues that the language used to describe these models matters, not only in scientific papers, but also in interactions with policy makers, media, business partners and customers. As such, it is crucial to understand the underlying computational mechanisms of LLMs and avoid using philosophically loaded terms that may lead to a misunderstanding of their true nature. This summary aims to provide an overview of Shanahan’s insights and emphasize the significance of thoughtful discussions surrounding the use of LLMs in society.
Introduction
The effectiveness of large language models (LLMs) can be measured in three ways, including their performance on benchmarks, qualitative leaps in capabilities, and their ability to reduce many human intelligence tasks to next token prediction. Shanahan’s paper “Talking about Large Language Models” focuses on the third point and warns against anthropomorphizing LLMs as they become more advanced. Shanahan argues that it’s a serious mistake to apply human intuitions to AI systems, particularly when those systems are fundamentally different from humans.
What LLMs really do
Consider how humans communicate with language. Wittgenstein states that human language use is an aspect of human collective behaviour, and it only makes sense in the wider context of the human social activity of which it forms a part. As we learn a language, we know what the moon is, we know that Neil Armstrong was the first human to walk on the moon. We believe in religion, or we understand what someone is saying when we are having a conversation with someone.
An LLM works differently. When an LLM learns (i.e. is trained) it is presented with training data called a corpus. Within the corpus there is a tremendous amount of language (sentences). The model forms a statistical distribution about the order of the sequence of the words. So rather than knowing that the first man on the moon was Neil Armstrong, the model infers that the most likely words to follow “the first man on the moon was” are the words “Neil Armstrong.” LLM’s do not understand the context of the sentence beyond what the next words should be.
As we think and communicate about large language models and AI, it’s important to understand how these models work.

LLMs and Intentional Stance
Intentional stance is a concept proposed by philosopher Daniel Dennett that refers to a way of interpreting the behavior of other entities, including humans, animals, and even machines. According to Dennett, when we take the intentional stance towards an entity, we treat it as if it has beliefs, desires, and intentions, and we try to predict its behavior based on those mental states.
For example, if we see a dog running towards a ball, we might assume that the dog has the intention of fetching the ball. This assumption allows us to make predictions about the dog’s behavior, such as where it will go and what it will do when it reaches the ball. Similarly, when we interact with other humans, we often assume that they have beliefs, desires, and intentions that motivate their behavior, and we try to predict their actions based on those mental states. We apply intentional stance as part of our daily communication quite frequently, through harmless anthropomorphizing of everyday objects. Shanahan argues that this is harmless, since the distinction between the objects intelligence and human intelligence is clear.
When considering LLMs and their capabilities, the distinction gets blurry. For example, when we can improve the performance of a reasoning task by including “think step by step” in a prompt to a model (Kojima), there is an overwhelming temptation to see the model as having human-like characteristics.
Shanahan insists that he is not arguing that a large language model can never be described in terms of beliefs or intentions, nor does it advocate for any particular philosophical concept. Rather, he suggests that such systems are different from humans in their construction yet human-like in behavior, so we need to understand their workings before attributing human-like capabilities to them.
Humans compared to LLMs
The article discusses the differences between human communication and how large language models (LLMs) like BOT respond to questions. When a human like Bob answers a factual question, he understands the context of the question, the person asking it, and the intent behind his response. He also relies on various techniques like direct observation, consulting resources, and rational thinking to ensure his response is accurate. On the other hand, BOT relies on statistical distributions to generate likely responses, and it requires a prompt prefix to generate appropriate responses that conform to the pattern of human conversation. Prompt engineering is a new category of AI research that explores how to adapt LLMs for various tasks.
The article highlights that while LLMs like BOT can answer questions, they lack the context, intent, and reasoning abilities of humans. Thus, prompt engineering is necessary to ensure that the responses generated by LLMs align with human conversation patterns. Although LLMs can perform various tasks without further training, prompt engineering remains relevant until better models of the relationship between what we say and what we want are developed.
Do LLMs Really Know Anything?
The versatility of large language models (LLMs) allows them to be used for various applications, including question-answering, summarizing news articles, generating screenplays, solving logic puzzles, and translating languages. However, LLM-based systems lack the communicative intent and beliefs of humans, and at a fundamental level, all they do is sequence prediction. While LLMs can “know” what words typically follow other words, they lack the means to exercise concepts like truth or falsehood in the way humans do. Therefore, we need to be careful when comparing LLMs to humans and avoid using language suggestive of human capabilities and patterns of behavior.
What about emergence?
Although large language models (LLMs) are powerful and convincing in their conversational abilities, they are ultimately only performing sequence prediction and do not have beliefs or knowledge in the way humans do. The emergence of unexpected capabilities in LLMs may be due to the large quantities of textual data they are trained on, and while it is acceptable to say that an LLM “encodes” or “contains” knowledge, it does not have access to external reality or the means to apply criteria of truth. The system as a whole must authentically engage with the world to meet these criteria.
External Information Sources
For a system to have beliefs about the world, it must have the ability to update its beliefs based on evidence from that world, which is essential for distinguishing truth from falsehood. While external sources such as trustworthy factual websites can provide criteria against which the truth or falsehood of a belief might be measured, it is important to consider the larger system of which the language model is a part. The language model itself is just a sequence predictor with no direct access to the external world. The absence of the mutual understanding that comes with human language use and our common evolutionary heritage is an important consideration when determining whether or not to speak of an AI system as if it “really” had beliefs.
Shanahan highlights the importance of recognizing the differences between AI systems and human beings when ascribing beliefs to the former. While updating a model in one’s head may be a reflection of one’s nature as a language-using animal in a shared world, the grounds for talk of beliefs and the behavioral expectations that come with such talk are absent when interacting with an AI system based on a large language model.
Vision Language Models (VLMs)
Shanahan also discusses the limitations of language and vision-language models (LLMs and VLMs) in terms of their communicative intent and ability to form beliefs about external reality. While LLMs can be used in question-answering systems with dialogue management, they do not have the capacity to form beliefs or intentions. On the other hand, VLMs can combine language models with image encoders and be trained on a corpus of text-image pairs to predict how a sequence of words will continue in the context of an image. However, the relationship between a user-provided image and the words generated by the VLM is merely correlated, not causal, which can lead to spurious correlations and inaccuracies in its predictions. Therefore, it may not be prudent to take literally talk of what a VLM “knows” or “believes.”
The limitations and capabilities of LLMs and VLMs depend on their embedding in larger architectures and their specific models. While they can be useful in certain applications such as question-answering and visual dialogue, they lack the capacity for communicative intent and forming beliefs about external reality. The potential inaccuracies and spurious correlations of VLMs in particular caution against taking their language and predictions literally.
What about Embodiment?
LLMs can be embedded in larger systems, such as physical robots or virtual avatars, which can interact with an external world. The SayCan system exemplifies this, where an LLM is embedded in a system that controls a physical robot to carry out everyday tasks in accordance with a user’s high-level natural language instruction. Despite being physically embodied and interacting with the real world, the way language is learned and used in a system like SayCan is very different from the way it is learned and used by a human. While embodied language-using systems incorporating LLMs are suggestive of what we might see in the future, their current limited repertoire of language use hardly bears comparison to the collective activity that language supports in humans.
Caution is needed when talking about embodied systems incorporating LLMs as their ability to understand and interact with the world is still limited. While an LLM can suggest actions to a robot, it does not consider what the environment actually affords the robot at the time. Therefore, while an engineer might say that a robot “knew” there was a cup to hand if it stated “I can get you a cup” and proceeded to do so, the wise engineer might object when asked whether the robot really understood the situation, especially if its repertoire is confined to a handful of simple actions in a carefully controlled environment.
Can Language Models Reason?
Shanahan discusses the ability of LLM-based systems to reason, which is harder to settle than the question of whether they have beliefs. Reasoning, which is founded in formal logic, is content-neutral, and LLMs can be applied to multi-step reasoning with clever prompt engineering. However, LLMs generate responses by mimicking well-formed arguments in their training set or prompt, and there are occasional mistakes.
Building a trustworthy reasoning system using LLMs requires embedding them in an algorithm that is similarly faithful to logic, as opposed to relying solely on prompt engineering. The only way to fully trust the arguments generated by a pure LLM is to reverse engineer it and discover an emergent mechanism that conforms to the faithful reasoning prescription. Therefore, caution should be exercised when characterizing what LLMs do as reasoning, properly speaking.
Shanahan concludes that while LLMs can be effectively applied to multi-step reasoning with clever prompt engineering, their ability to reason is limited by their reliance on mimicking well-formed arguments and occasional mistakes. Trustworthy reasoning systems using LLMs require embedding them in algorithms that are faithful to logic, and caution should be exercised when characterizing what LLMs do as reasoning.
What about Fine-Tuning?
Consider the use of supervised fine-tuning and reinforcement learning from human feedback in contemporary LLM-based applications. These techniques can improve a model’s responses, accuracy, and filter out toxic language. However, they do not significantly muddy our account of what large language models “really” do. The result is still a model of the distribution of tokens in human language, albeit slightly skewed. Fine-tuning does not change the nature of the final product, which is a model of the statistical distribution of words in the vast public corpus of human language.
Shanahan provides example of a controversial politician, Boris Frump, to illustrate the impact of fine-tuning on language generation. Before fine-tuning, the raw LLM might yield two equally probable responses, one highly complimentary, and the other crude. However, a model that has been fine-tuned using RLHF would produce more politically neutral responses. The quantity of such examples in the training set would have to be large enough to ensure that the most likely responses from the trained model are those that raters and users would approve of.
What counts most when we think about the functionality of a large language model is not so much the process by which it is produced but the nature of the final product. A conventionally trained raw LLM is equivalent to a model trained completely from scratch with RLHF. The thought experiment illustrates that what is most important is the statistical distribution of words in the vast public corpus of human language that the model represents.
Conclusion: Why is this important?
The use of terms like “belief”, “knowledge”, and “reasoning” in reference to large language models (LLMs) can be problematic because it may lead to anthropomorphism and the assignment of more weight to these terms than they can bear. LLMs are fundamentally different from human beings, lacking a shared “form of life” that underlies mutual understanding and trust among humans. As such, they can be inscrutable and present a patchwork of less-than-human with superhuman capacities, of uncannily human-like with peculiarly inhuman behaviours. The way we talk about LLMs matters not only in scientific papers but also when interacting with policy makers or speaking to the media.
The sudden presence of LLMs among us may require a shift in the way we use familiar psychological terms or the introduction of new words and phrases. However, it takes time for new language to settle, and it may require an extensive period of interacting with these new kinds of artefacts before we learn how best to talk about them. In the meantime, we should resist the siren call of anthropomorphism and be careful not to assign more weight to these terms than what the LLMs realistically reflect.
References:
- Shanahan, Murray, Talking About Large Language Models, 2022, https://arxiv.org/abs/2212.03551
- Takeshi Kojima, S. Gu, Machel Reid, Yutaka Matsuo, Yusuke Iwasawa, Large Language Models are Zero-Shot Reasoners, 2022, https://arxiv.org/abs/2205.11916
- Dennett, D. C. (1987). The intentional stance. MIT press

Gartner Data & Analytics Summit Takeaway: “Why is nobody listening?”
Is your data AI-ready? That was a consistent theme at this year’s Gartner Data & Analytics Summit in Orlando, Florida. There were many Gartner keynotes and analyst-led sessions that had...
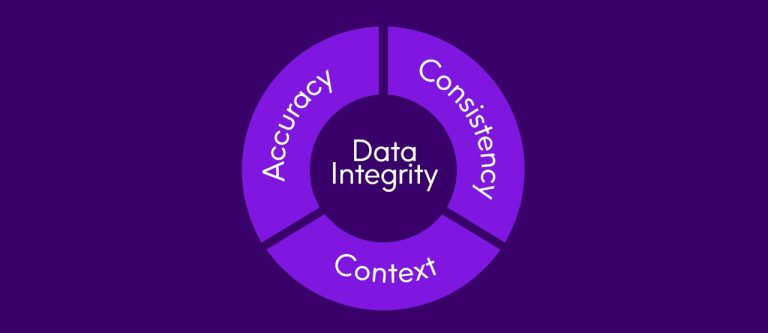
What is Data Integrity?
Key Takeaways: Data integrity is achieved when data has maximum accuracy, consistency, and context – giving you the power to trust your data and make better business decisions. The journey to...

AI-Driven Data Integrity Innovations to Solve Your Top Data Management Challenges
Key Takeaways: New AI-powered innovations in the Precisely Data Integrity Suite help you boost efficiency, maximize the ROI of data investments, and make confident, data-driven decisions. These...